Managing the Mental Load of Infinite Code
By Julian Massarani
Three prototypes before lunch
Our CTO told the productivity side of this story in Part 1: We Told 300 Engineers to Stop Writing Code. The short version: we went all-in on AI-assisted development, and output went up across the board. This is the sequel from inside the team. What it’s actually like when building gets cheap and the hard part moves to your head.
A few weeks ago I sat down on a Tuesday morning, opened a blank file, and by lunch I had three working prototypes for an idea I’d been carrying around for a month. None of them were finished. All three were good enough to argue about. The biggest shift I’ve noticed personally is I’m no longer debating what I can build within X timeframe. It’s more: what should I build out of all the ideas we have?
Mozilla AI put it well earlier this year: “when the cost of building collapses, the cost of building the wrong thing increases dramatically.” That sentence has been living rent-free in my head. And if that’s true, the bottleneck hasn’t disappeared, it’s just shifted.
A year ago, an idea took days of spec writing before anyone could react to it. You’d describe a recommendation system in a doc, schedule a review, watch six people interpret the same paragraph six different ways, and only then start to build. Now the first thing we do is build it. A rough version. Not perfect, but real enough that you can look at it and say “this is compelling” or “this would cause a problem” or “I didn’t realize the edge case looked like that.”
Engineers and PMs are building things together at the prototype stage now. Sometimes the PM builds it, sometimes engineering does. Product-market fit and engineering viability get assessed in the same conversation, looking at the same artifact, on the same afternoon. Gergely Orosz captured this well in “When AI writes almost all code”: tech-lead instincts and product-mindedness become more valuable, not less. What differentiates good work isn’t the ability to generate ideas anymore. It’s the ability to discriminate between them.
This is the better and more fun version of the job. However, coding used to be the downtime. You’d spend a long time thinking through product and technical considerations, and then there was this break when you’d done the thinking and were just putting it together. That phase is gone. The thinking starts earlier, and I’ve found it never quite stops.
Learning to wrangle the new normal with dopamine machines
It’s not burnout; we take that seriously and actively work against it. What I’m describing is something different: a constant low hum of half-finished thoughts. Eight ideas in motion at any given moment, each at a different stage, each with a small voice saying, “You could sit down right now for 30 minutes and build me.”
While it’s no surprise increased productivity leads to more time spent in code reviews, I also have to manage my own infinite code. Not just everyone else’s output. My own: the explosion of my own ideas, prototyped faster than I can decide whether they’re worth pursuing.
We’re working with dopamine machines. The feedback loop from idea to artifact is so tight, so satisfying, that the work doesn’t stop on its own. One idea finishes, another starts, no natural seam between them. Energizing and exhausting in the same breath.
The data backs this up. DORA’s 2025 research found roughly 67% more PR contexts per day, more stalled work, more restarts, with “operational consequences that compound over time even when they do not immediately register as burnout.” That clause is the one I keep coming back to. Addy Osmani calls it “comprehension debt”: the gap between code that exists and code anyone has understood. I’d add that it applies to your own ideas too. You generated them faster than you can evaluate them, and switching between half-finished thoughts is the part that costs you.
Three agents and a reality check
A real morning, in present tense.
It’s 11:45am, I have three agents working in parallel, each implementing a piece of a plan I wrote at 9:14 am. One is the deep brainstorm, a recommendation flow I’m actively shaping. I’m fully in it. The second is a small refactor that mostly knows what it’s doing; I check on it every fifteen minutes. The third is a research thread I kicked off and will not seriously look at until tomorrow. That’s my limit. Three. Maybe.
It was humbling to discover that. I thought I could run more. The tools make parallelism feel possible. The threads don’t visibly compete for attention the way meetings do. But human cognition didn’t get an upgrade. One deep brainstorm and a small babysat task on the side is roughly my ceiling. More than that and I end up producing lower quality work or build the same thing I already built a week ago, but forgot about. Plans get sloppier. Reviews get more superficial. The prototype I would’ve shipped at 4 pm becomes the prototype I have to revisit later in the week.
It’s a sprint vs. marathon problem: you’re essentially reviewing a PR every time you get code from an agent. You front-load thinking into planning and prompts, then switch into review mode repeatedly throughout the day. Part 1 mentioned a “rule of three” heuristic, no more than three agents at a time, and I’ve found that largely holds, assuming only one of those tasks requires full focus.
So: the load is real. What do you do about it?
Engineering it away
The instinct is to reach for the wellness toolkit. Take a vacation. Block focus time. Pace yourself. None of that is wrong. Pacing matters, recognizing the dopamine pull matters, managers watching for overwork matters.
But self-care alone won’t carry you, because the load isn’t only emotional. It’s environmental. The biggest lever is engineering the friction out of the path.
On the machine learning side, we used to hand-craft model training notebooks for every training experiment, kick off a 3-4 hour run, and hope nothing went wrong. If it failed — out of memory, stale data, wrong cluster sizing, or the idea just didn’t pan out — you’d triage it, fix it, restart, and lose a day. We sometimes went through six failed iterations on one experiment before landing on the right configuration. Each failure taught us something, and each fix was stuck in one person’s head or one notebook.
So we built a framework that encodes all of those lessons. You write a short spec — maybe 15 lines — describing what you want to test against the baseline. The runner generates the notebooks, validates everything locally in seconds, handles the cluster configuration and memory tuning that used to blow up on us, and submits the job. Our framework can even do opportunity finding and exploration, one of the more expensive parts of traditional machine learning workflows. It then runs unattended, compares results against the baseline automatically, and reports back whether the experiment was better, flat, or worse. All the knowledge from those six failed runs is baked into the tooling so the next person doesn’t re-learn them.
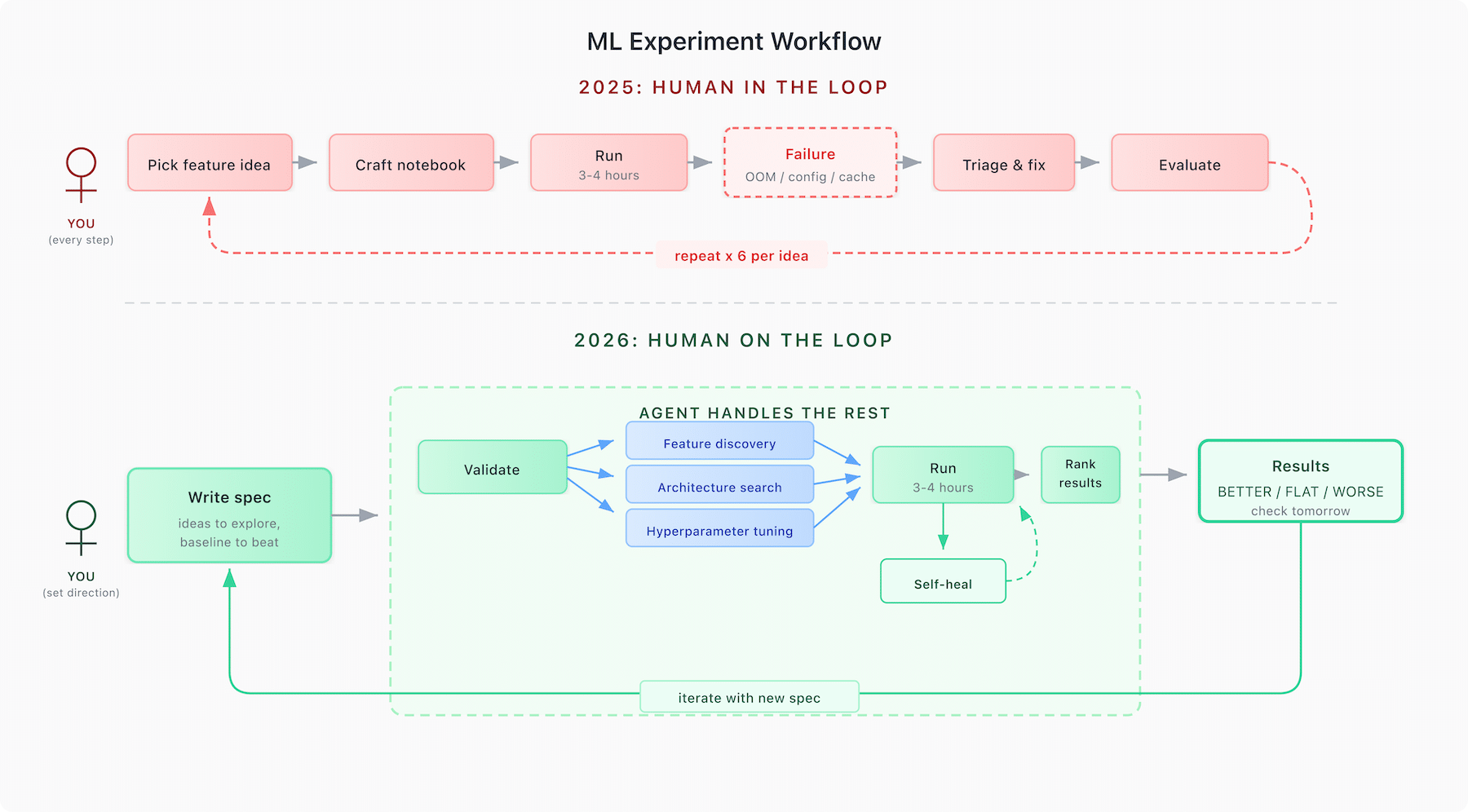
Mitchell Hashimoto calls this “harness engineering”: you’re on the loop rather than in the loop. You maintain the harness; you don’t review every output. That’s the only version of this that scales. We wrote about learning this the hard way in a previous post on operationalizing GenAI. The lessons apply well beyond ML.
DX’s Q4 2025 research found that AI saves a few hours a week per engineer, but meetings, interruptions, and review delays cost more than that. The small things compound: a PR waiting on review, a flaky test you have to re-run, a manual approval step that exists because nobody built the automated check, an unnecessary meeting. Each one is minor on its own, but when you’re running more threads than ever, the drag multiplies. The lever isn’t the AI tool, it’s reducing the friction around it.
Building that framework wasn’t on anyone’s roadmap a year ago. It wasn’t worth the investment when building was slow. Now it is, and that’s where the bigger shift comes in.
“We’d never get to that” became “we should do that this week”
In 2025 we had AI, but we were still solving problems like it was 2024. See an issue, drop in a fix, move on. Same problems, same methodology, just a little faster. For a while that’s how most of us were operating, myself included.
2026 is different. That training framework is one example, but the pattern is everywhere. There are entire classes of solutions that weren’t worth building when building was expensive. Robust prevention instead of repeated manual work. Automated systems that quietly hold a property we used to maintain by hand. The ROI math changed underneath us, and a lot of “we’d never get to that” work moved into “yeah, we should do that this week.” This is the question I’m asking more often than I used to: how can we prevent this from ever happening again in a robust way? That question used to feel like an indulgence. It doesn’t anymore.
Bainbridge wrote in 1983, in Ironies of Automation, that the more sophisticated the automation, the more demanding the human role becomes. Forty years later that feels less like a warning and more like a job description. The human role is choosing what to point all this capacity at.
The most interesting question on my desk right now is not “how do I build this?” It’s “what’s worth building, and what would the robust version look like?”
Being a beginner again
If I could send one message back to myself a year ago, it would be this: you’re not going to be the expert on this. Be open to feedback. You may have been a fantastic engineer, and that may still be true, but you do not yet know all the ways building with these tools works. Listen to other people. Listen to junior engineers, who often arrive without the muscle memory to fight. Unlearning is actually harder than learning something for the first time. Change your mind frequently. Get comfortable being a beginner again.
This is the most interesting version of the engineering job that has ever existed. The mental load is real. Smart teams (and I’m lucky to work with many) are learning to carry it together. The work is more about judgment and taste than at any point in my career. Tired but excited is, I think, the honest version of how a lot of us feel right now, and I’d rather be tired and excited than the alternative.
We’ll figure this out collectively, the way we figured out the last several waves. The tools will change again. The job will change again. The people who’ll do well are the ones who treat that as the most interesting part — not the part to wait out.
I’m excited for this new working model. More robust prototyping means we can efficiently deliver safer, more effective tools for patients and providers across Zocdoc.
Julian Massarani is a Staff Machine Learning Engineer and tech lead for the Sponsored Results team at Zocdoc.